

Search Engine Indexing: How It Works
Search engine indexing is a crucial component of the search engine process, allowing search engines to quickly and efficiently return relevant results to users.
TABLE OF CONTENTS
- Introduction to Search Engine Indexing
- How Search Engines Crawl the Web
- How Do XML Sitemaps Help Search Engine Indexing?
- How Do Canonical Tags Help Search Engine Indexing?
- Building and Updating a Search Engine Index
- Ranking and Returning Search Results
- The Role of Backlinks and PageRank in Indexing
- The History of Search Engine Indexing
- How the Market Brew Indexing Layer Works
In this article, we will delve into the inner workings of search engine indexing, including how search engines crawl the web, how they build and update their indexes, and how they use these indexes to rank and return search results.
We will also discuss the role of backlinks, PageRank, and other ranking factors in search engine indexing, and explore the history of search engine indexing with a focus on the early search engine Backrub (later known as Google).
Introduction to Search Engine Indexing
Search engine indexing is the process of collecting, parsing, and storing data to facilitate fast and accurate information retrieval.
The purpose of indexing is to create an organized database of web pages and their content, allowing search engines to quickly and accurately display relevant search results to users.
When a search engine crawls the web, it follows links to discover new pages and add them to its index. The process of indexing involves analyzing each page's content, including the text, images, and other media, to determine its relevance and significance. The search engine uses various algorithms and techniques to analyze the content and assign a relevance score to each page.
The indexing process is essential for search engines to provide accurate and relevant search results. Without indexing, search engines would have to search the entire web every time a user entered a query, which would be slow and impractical. By indexing the web and storing the data in a structured and organized manner, search engines can provide quick and accurate search results.
The indexing process is not static, and it is constantly updated as new pages are added to the web and existing pages are modified. Search engines continually crawl the web to discover new pages and update their index, ensuring that the latest and most relevant information is available to users.
There are several factors that can affect a page's relevance and ranking in search engine results. These factors include the quality and relevance of the page's content, the number and quality of external links pointing to the page, the page's loading speed, and the presence of keywords and other relevant terms.
In addition to indexing web pages, search engines also index other types of content, such as videos, images, and news articles. This allows users to search for a wide range of information and find relevant results from multiple sources.
The indexing process is crucial for search engines to provide accurate and relevant search results to users. By constantly crawling and indexing the web, search engines ensure that the latest and most relevant information is available to users. This allows users to quickly and easily find the information they are looking for, making the internet a valuable resource for information and knowledge.
How Search Engines Crawl the Web
Search engines are the backbone of the internet, providing a means for users to find the information they are seeking. But how do they actually work? How do they crawl the vast expanse of the web, sifting through billions of pages to find the most relevant results for a given query?
The first step in the process is for a search engine to send out its "spiders," also known as crawlers or robots. These are software programs that automatically visit web pages and follow links to other pages, systematically exploring the web. As they crawl, they collect information about the content of each page, such as the words used, the links to and from the page, and other metadata.
This collected information is then sent back to the search engine's servers, where it is processed and indexed. This index is essentially a giant database of all the web pages that have been crawled, organized in a way that allows the search engine to quickly find relevant results for a given query.
But not all pages are crawled and indexed equally. Search engines use various algorithms and criteria to determine which pages are most important and should be prioritized in the crawling and indexing process. These factors can include the quality and relevance of the content, the number and quality of external links pointing to the page, and the overall popularity of the page.
Once the index is created, the search engine is ready to serve up results for users' queries. When a user enters a query, the search engine uses its algorithms to quickly search the index and identify the most relevant pages. These pages are then ranked and presented to the user, with the most relevant and valuable pages appearing at the top of the search results.
The process of crawling and indexing the web is ongoing, as new pages are constantly being created and existing pages are updated. Search engines must continuously crawl the web to ensure that their indexes are up-to-date and relevant for users.
In short, search engines crawl the web by sending out spiders to collect information about web pages, which is then processed and indexed. This allows the search engine to quickly serve up the most relevant results for a given query. But the process is ongoing, as new pages are constantly being added to the web and existing pages are updated.
How Do XML Sitemaps Help Search Engine Indexing?
XML sitemaps are a crucial tool for website owners and developers to inform search engines about the pages on their site that are available for crawling.
These sitemaps help search engines discover and index new pages, as well as any changes made to existing pages.
A sitemap is a file that contains a list of all the URLs on a website, along with additional metadata about each URL such as when it was last updated and how often it changes. XML stands for Extensible Markup Language, and is a standardized format for organizing and storing data.
One of the primary benefits of using an XML sitemap is that it provides a way for website owners to explicitly tell search engines about all the pages on their site. This is especially important for websites with a large number of pages, or those that have content that is not easily discoverable by search engines through normal crawling.
Another benefit of using an XML sitemap is that it can help search engines more efficiently crawl a website. By providing a complete list of URLs, search engines can prioritize which pages to crawl based on the metadata included in the sitemap. This can help save crawl budget, as it allows search engines to focus on the most important pages first.
In addition to helping search engines discover and index new pages, XML sitemaps can also be used to notify search engines of any changes made to existing pages. This is especially useful for websites that regularly publish new content or make updates to existing pages. By submitting an updated sitemap to search engines, website owners can ensure that search engines are aware of these changes and can update their index accordingly.
There are several ways to create and submit an XML sitemap to search engines. One common method is to use a sitemap generator tool, which can automatically create a sitemap based on the URLs on a website. Once the sitemap is generated, it can be submitted to search engines through the webmaster tools provided by Google and Bing.
It's important to note that XML sitemaps are just one of many factors that search engines use to determine how to rank pages in their index. While a sitemap can help ensure that search engines are aware of all the pages on a website, it does not guarantee that those pages will rank well.
To improve the ranking of a website's pages, it's important to focus on other factors such as the quality and relevance of the content, the structure and navigation of the website, and the number and quality of external links pointing to the site.
In summary, XML sitemaps play a crucial role in helping search engines discover and index the pages on a website. By providing a complete list of URLs and metadata about those pages, sitemaps can help search engines more efficiently crawl a website and ensure that the most important pages are indexed first. While sitemaps are just one factor in determining the ranking of a website's pages, they can be a useful tool for website owners looking to improve their search engine visibility.
How Do Canonical Tags Help Search Engine Indexing?
Canonical tags, also known as "rel=canonical," are HTML elements that help search engines understand which version of a webpage to index. They are used to prevent duplicate content issues, which can occur when the same content is accessible through multiple URLs.
This can happen for a variety of reasons, such as the use of URL parameters, www and non-www versions of a domain, or even just simple typos in URLs.
Duplicate content can be a problem for search engines because it dilutes the value of the content, making it more difficult for search engines to determine which version of a webpage to display in search results. This can lead to a poorer user experience and can even lead to lower search rankings.
To prevent these issues, webmasters can use canonical tags to specify which version of a webpage is the "canonical" or preferred version. This tells search engines which version of the content they should index and display in search results.
To use a canonical tag, you simply add a link element with the attribute "rel=canonical" to the head of the HTML of the webpage that you want to designate as the preferred version. The "href" attribute of the link element should contain the URL of the preferred version of the webpage.
It's important to note that canonical tags are just hints to search engines, and they may choose to ignore them if they believe that another version of the content is more relevant. However, in most cases, search engines will honor the canonical tags and index the designated version of the content.
Canonical tags can be very useful for webmasters who want to consolidate their content and ensure that the search engines are indexing the correct version of their pages. They can also be used to merge multiple pages with similar content into a single page, which can help to improve the user experience and make it easier for search engines to understand and index the content.
In addition to helping with duplicate content issues, canonical tags can also be useful for improving the organization and structure of a website. By designating certain pages as canonical, webmasters can help search engines understand the relationship between different pages on their website and how they fit into the overall site hierarchy. This can help improve crawl-ability and index-ability of the website, leading to better search rankings and higher visibility in search results.
In summary, canonical tags are a useful tool for webmasters who want to ensure that search engines are indexing the correct version of their content and for improving the organization and structure of a website. They can help to prevent duplicate content issues and improve the user experience by consolidating similar content into a single page. By using canonical tags, webmasters can help improve the crawl-ability and index-ability of their website, leading to better search rankings and higher visibility in search results.
Building and Updating a Search Engine Index
A search engine index is a database of web pages that have been crawled and indexed by a search engine. This index is used to provide relevant and accurate search results to users when they search for a specific query.
Building and updating a search engine index is a crucial part of a search engine's operations and requires careful planning and execution.
The first step in building a search engine index is to crawl the web and collect web pages. This is done using specialized software called a web crawler, which follows links on web pages to discover new pages and add them to the index. The crawler collects information about each page, such as its content, links, and meta tags, which are used to determine its relevance to a user's search query.
Once the web pages have been collected, they are indexed by the search engine. This process involves analyzing the collected information and organizing it in a way that allows for efficient retrieval. It will even look at things like 301 redirects in order to determine which pages to index. The index is typically organized using an inverted index, which maps keywords to the web pages that contain them. This allows the search engine to quickly retrieve relevant pages when a user searches for a specific keyword.
Once the index has been built, it needs to be regularly updated to ensure that it remains accurate and relevant. This is done through a process called recrawling, where the web crawler revisits web pages that have already been indexed to check for any changes or updates. If a page has been updated, the search engine will update the information in the index accordingly.
To improve the accuracy and relevance of search results, search engines also use algorithms and machine learning techniques to rank web pages. These algorithms take into account various factors, such as the relevance of a page to the user's query, the quality and credibility of the page, and the number and quality of links pointing to the page. This allows the search engine to return the most relevant and useful pages at the top of the search results.
In addition to regular recrawling and ranking, search engines also need to handle the constant influx of new web pages being added to the internet. This requires the search engine to constantly crawl the web to discover new pages and add them to the index.
Ranking and Returning Search Results
Ranking and returning search results is an essential part of the search engine process. The goal of ranking and returning search results is to provide users with the most relevant and useful information for their query.
The first step in ranking and returning search results is to gather and organize the information. This involves crawling the web to gather web pages, indexing the information on those pages, and storing it in a database.
Once the information has been gathered and organized, the search engine uses algorithms to rank the results. These algorithms take into account a variety of factors, including the relevance of the content to the user's query, the quality and credibility of the source, and the user's previous search history and behavior.
The search engine also considers the popularity of the content, as well as the presence of keywords and phrases in the user's query. This helps to ensure that the most relevant and useful results are returned to the user.
In addition to ranking the results, the search engine also needs to consider how to present the information to the user. This involves organizing the results into a format that is easy to read and understand, as well as providing additional information, such as the title, description, and source of each result.
The search engine may also provide additional features, such as the ability to filter results by date, relevance, or other criteria. This allows users to quickly and easily find the information they are looking for.
Finally, the search engine may blend different types of results. This has spawned different fields of SEO like Local SEO, Video SEO, and others.
Overall, ranking and returning search results is a crucial part of the search engine process. It allows users to quickly and easily find the information they are looking for, and helps to ensure that they receive the most relevant and useful results. By carefully considering a variety of factors and presenting the information in a clear and organized manner, search engines are able to provide users with a valuable and effective tool for finding the information they need.
The Role of Backlinks and PageRank in Indexing
Backlinks and PageRank are two important factors in the process of indexing a website. Indexing refers to the process of adding a website or its pages to a search engine’s database, making it discoverable and accessible to users through search results.
Backlinks, also known as inbound links, are links from other websites that point to a specific page on a website. These links act as a vote of confidence and credibility for the linked page, indicating that the content on that page is valuable and worth exploring.
In the context of indexing, backlinks play a crucial role. Search engines use backlinks as a signal of the popularity and relevance of a website or page. The more backlinks a website has, the more likely it is to be indexed and rank higher in search results.
Additionally, the quality of the backlinks also matters. Links from reputable and high-authority websites carry more weight and can improve a website’s indexing and ranking. On the other hand, links from low-quality or spammy websites can harm a website’s indexing and ranking.
Another important factor in indexing is PageRank, which is a ranking system developed by Google to measure the importance and relevance of a website or page. PageRank uses backlinks as a key factor in its algorithm, but also takes into account other factors such as the quality and relevance of the content, the user experience, and the overall trustworthiness of the website.
A website or page with a high PageRank is more likely to be indexed and rank higher in search results. PageRank is constantly updated, and the ranking of a website or page can fluctuate based on its performance and the changes in the algorithm.
In summary, backlinks and PageRank play a crucial role in the indexing of a website. Backlinks serve as a vote of confidence and credibility for a website or page, and the quality and quantity of backlinks can affect its indexing and ranking. PageRank, on the other hand, uses backlinks and other factors to measure the importance and relevance of a website or page, and can impact its indexing and ranking.
The History of Search Engine Indexing
The history of search engine indexing dates back to the early days of the internet. In the early 1990s, search engines were developed to help users navigate the vast amount of information available on the internet. These early search engines used simple algorithms to index and rank websites based on the number of times a specific keyword appeared on a website.
One of the first search engines to be developed was Archie, which was created in 1990 by Alan Emtage, a computer science student at McGill University. Archie indexed the contents of FTP archives and allowed users to search for specific files using keywords. It was followed by Gopher, which was developed at the University of Minnesota and allowed users to search for specific files within a network of servers.
In 1993, the first web search engine was developed, called World Wide Web Wanderer. It was created by Matthew Gray, a graduate student at MIT, and was used to track the growth of the internet by indexing new websites as they were added. However, it was limited in its capabilities and could only index a limited number of websites.
In 1994, the first major search engine, called Yahoo, was created by Jerry Yang and David Filo. Yahoo used a combination of human editors and algorithms to index and rank websites based on their content and popularity. This was a major step forward in the development of search engines, as it allowed users to search for specific information on the internet.
In 1996, a new search engine called AltaVista was developed by Digital Equipment Corporation. It was the first search engine to use advanced algorithms to index and rank websites based on their content and relevance to the user's search query. This marked the beginning of the era of advanced search engine algorithms, which would continue to evolve over the next two decades.
In 1997, Google was founded by Larry Page and Sergey Brin, two graduate students at Stanford University. Google used a unique algorithm called PageRank, which ranked websites based on the number and quality of links pointing to them. This algorithm revolutionized the way search engines indexed and ranked websites, and Google quickly became the dominant search engine on the internet.
How the Market Brew Indexing Layer Works
Market Brew's search engine models use web crawlers to collect data from the internet. These crawlers scan the web, following links from one page to another and collecting information as they go. As the crawlers collect this data, the search engine stores it in an indexing layer.

The indexing layer is a critical component of Market Brew's search engine models. It considers many aspects of the crawling process, including errors and redirects that can guide the indexing layer as to which pages to index or not.
It uses the database management system PostgreSQL and the Lucene Query Parser to create indexes on the data collected by the crawlers.
These indexes make it possible for the search engine model to quickly and efficiently retrieve the data it needs to perform all of its calculations and algorithmic formulas.
The indexing layer allows Market Brew's search engine model to operate in a manner similar to Google.
When the search engine models simulate a search, the Market Brew search engine model retrieves the relevant data from its index and uses various algorithms to determine the most relevant results.
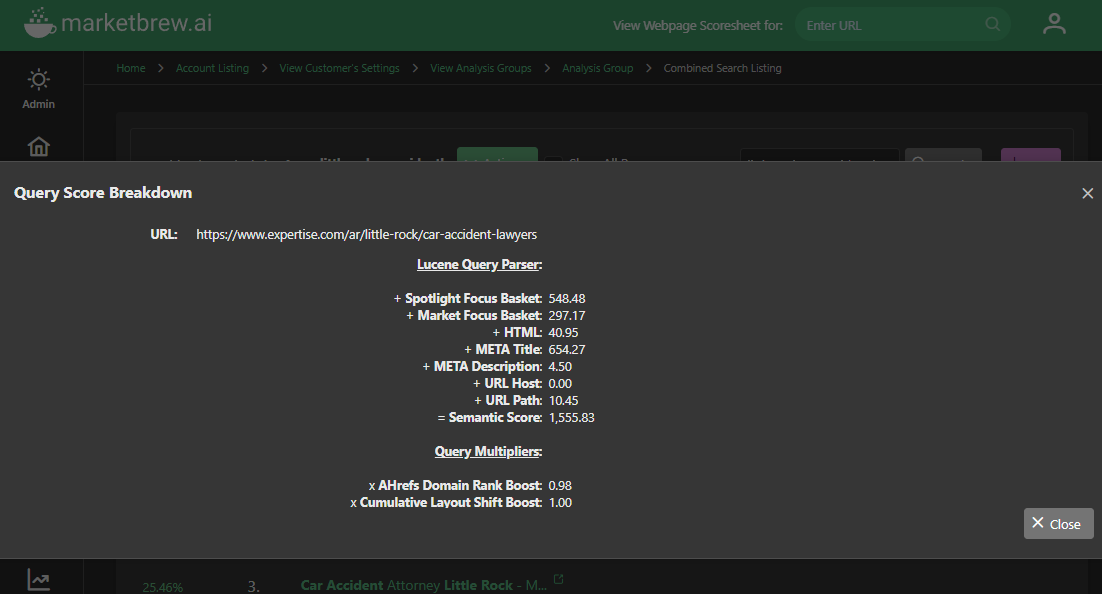
The indexed data is used to calculate factors such as the relevance of a web page to a user's query, the popularity of a page, and the quality of the content on the page.
The indexed data is also used to help the search engine understand the relationships between different pages on the web. For example, if two pages link to each other, the search engine can infer that they are related and may be more relevant to a user's query than other pages that do not have this relationship.
Overall, the indexing layer is a crucial component of Market Brew's search engine. It allows the search engine to quickly and efficiently retrieve the data it needs to perform its various algorithms and calculations. This is essential for providing users with accurate and relevant search results.
Schedule a demonstration today via our Menu Button and Contact Form to discover how we engineer SEO success.
You may also like
Guides & Videos
Others
Essentials for Content Strategy Success
Guides & Videos
Recommendation Engines Boost to SEO
Guides & Videos